
Research group in emergent narratives
Reviews and “Let’s play” of LabLabLab games
Blog posts
- http://oujevipo.fr/general/3690-a-tough-sell/
- http://www.gamespressjapan.com/a-tough-sell/
- http://jayisgames.com/review/link-dump-friday-n-373.php
- http://jayisgames.com/review/link-dump-friday-n-371.php
- http://xf-gaming.de/2015/03/22/a-tough-sell-stirb-schneewittchen/
Let’s Play Videos
https://www.youtube.com/watch?v=BD4DVESeNi0
https://www.youtube.com/watch?v=VTa78bY6-yM
Working with Chatscript and Unity
Author: Samuel Cousin
This document aims to explain most of the technical process and methodology that has been developed by LabLabLab while implementing three natural-language conversational games using ChatScript and Unity. This is not a replacement for either framework’s documentation, but rather something akin to a developer journal, or a specific use case with detailed examples. It should allow like-minded researchers to duplicate and expand this project further.
Overview
All three of LabLabLab’s games use a combination of ChatScript for the natural language component and a Unity made interface exported as a web player package. The frontend and backend communicate through the websocket protocol, which operate over TCP sockets.
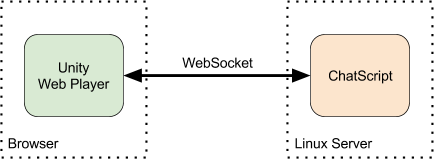
Fig. 1, Simplified diagram of the back/front components
Before going further, one should definitely look-up introductory documentation both to ChatScript and Unity, so as to understand how they work from a high level: see this Unity video for a quick introduction on how it handle 2D games; the ChatScript Input to Output Overview should explain the basis, although to make to most of this document, I would recommend reading through the Basic User Manual.
Because most of the content is based on the LabLabLab’s games, the reader should also play a bit with our games to understand their gameplay mechanics and how it relate to the technology we’re using.
ChatScript
At the core of the project resides ChatScript, a software created and maintained almost solely by Bruce Wilcox since 2010. It is a complete chatbot engine, used to create complex and rich “conversational robots”, with whom the user can have believable natural language (english) conversations. It implement everything that one might need to do so: natural language parsing, extensive ontologies, conversation volley & rejoinder system, wildcard matching, etc.
While ChatScript is now well into version 6, the versions used by LabLabLab in production are 5.21 (A Tough Sell) and 5.52 (SimHamlet & SimProphet).
Fundamentals
ChatScript (CS) works by using a control script to direct user inputs towards different topics, where they will be responded to (or not). The matching rules/responses pairs are implemented using a mix of english, operators, modifiers and functions. Topics are thematically arranged, user-created collections of rules/response pairs and keywords.
The control script is a topic as well, but one that is used as a dispatcher for other topics, which makes it a bit less readable. For most usage, the default control script should be sufficient and behave more or less like this:
- Determine the current topic of conversation based on keywords or state of execution;
- Try and match the input sentence within the current topic;
- If there is multiple matches, pick the first one;
- If there is no match, try to find a non-keyword response within that topic (this is called a gambit);
- If there is no match and no gambit available, try in other topics
- If there is no matches at all, fall-back to a “catch all” topic where the matching rules are less strict;
When a response is found, the execution stops, the rule/response pair is marked as used, and the response is sent to the user.
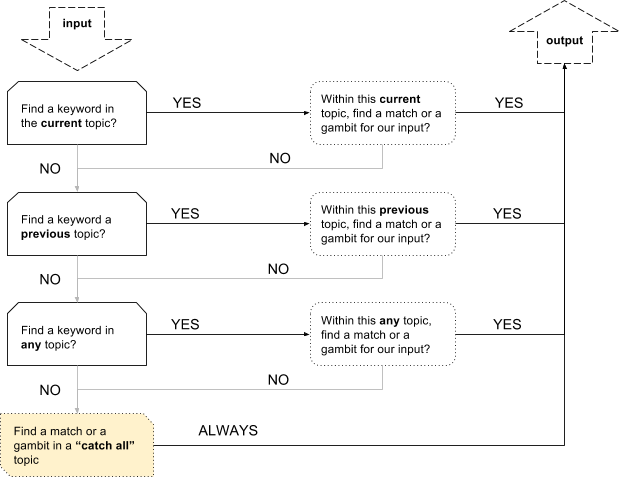
Fig. 2, Execution of a basic CS control script
After determining which topic is the most relevant for a given input, CS parses this input to find a rule/response pair. For a concise explanation of the matching patterns available in CS, one should refer to the Pattern Redux documentation available from the Github repository. Of course, natural language forces us to assume that most of the time the input will use improper grammar or be incomplete, and CS makes provisions for this.
File structure
Let’s look at how this come together in SimHamlet, first by looking at the file structure inside the /RAWDATA/GRAVEDIGGER folder:
.
├── a_concepts.top
├── claudius.top
├── gertrude.top
├── hamlet_jr.top
├── hamlet_sr.top
├── introduction.top
├── laertes.top
├── ophelia.top
├── polonius.top
├── rosencrantz_guildenstern.top
├── z_catchall.top
├── z_culprit.top
├── z_pronouns.top
└── z_simplecontrol.top
Fig. 3, Directory structure of SimHamlet
First off, all CS files use the .top extension. One can also see that we use prefixes to identify special files. In this case, a_concepts.top is not a topic, but rather a place where we gathered all of our custom concepts. Since concepts can be compared to constant variables, using a single file to aggregate all of them curbs the problem of having to hunt for them in dozen of files when we want to change something. It is also important to note that having an a_ prefix insures that our concept file is compiled first and made available to files loaded after.
Our regular topics are simply named with the topic they cover, in this case mostly character names. If they would reference or depend on each other in specific ways, one would want to prefix them them with a number to dictate when they are individually compiled.
Finally, we have prefixed our system topics with z_, which means that they will be compiled after all other files. These files contain most of our script logic and concatenate our controls, making them more easily maintainable. Our control script obviously qualify as system topic (z_simplecontrole.top), just as our “catch all” topic do (z_catchall.top).
Topics
Topics are paramount in ChatScript. From a structure standpoint, they should be viewed as classes in OOP: they are used to make the code manageable & reusable, while splitting it up in logical, thematic files (.top). This underline the importance of a structured outline, since the interactions will need to be divided and grouped together; the clearer the program outline, the easier it will be to break it into parts.
What these topics consist of depend solely on what kind of narrative arcs we want to create. For SimProphet we used broad themes such as death, politics and sex to group our matching patterns. For SimHamlet the topics were centered around the characters in the play: Ophelia, Laertes, Polonious and so on. Thorough, requirements from the narratives dictated the composition of topics, once again denoting the importance of mapping out conversational paths well before implementing them. Topics are built around keywords. Keeping in mind the control script outlined above (Fig. 2), consider this arrangement:
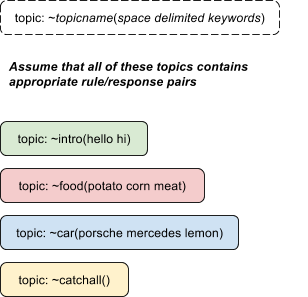
Fig. 4, Topics name and keyword
Assuming that the current topic is ~intro and that the previous topic is ~car :
- The input “Do you own a porsche?” will check in ~intro topic and not find the keyword, then move to the previous topic (~car), find the keyword, find an hypothetical match and return its response.
- The input “I love meat” will check in the ~intro topic and not find the keyword, check ~car and not find the keywords, then will check ~food, find the keyword, find an hypothetical match and return its response.
- The input “I am a dog” will find no keyword or matches in any of the topics, and will go look up in ~catchall for a response.
This further illustrate why catch all topics should always contain mostly generic rule/responses & gambits, alongside permanent responses (see the ^keep and ^repeat functions). This insures that all inputs are appropriately responded to, even when we find no match at all.
System topics
A different type of topics are system topics, which are used to collect rules that apply to the execution of our script. Marking these topics as system topic will make sure that they are prioritized, never “forgotten” and that their content will not be checked for spelling mistakes. The control script, for instance, is a system topic. By separating our logic code from our regular response topics, we insure that we can maintain our bot more easily and completely oversee the flow of execution through the control script.
System topics are very important to enforce structure and sanitize or process user input before responding to it. For example, a good candidate for a system topic would be a piece of script that parse the input for a certain word, replace it, and then direct the input the another topic for an actual response. For a list of topic flags (modifiers that can be added to your topics), see page 6 of the Advanced User Manual.
Rule and response pairs
One way to view rules and response pairs is as if statement with words being concurrent boolean conditions: if the word is matched, we get a true and move to the next part of the operation. If all operations add up to true, the bot will offer the response. This behavior appears naturally when we start adding literal boolean condition in our match patterns, so the bot respond only if certain conditions that might have nothing to do with the input are met.
If you have not already, have a look at the Input to Output Overview to get a grasp of how content is matched and responded to in CS.
The simplest form of a rule / response pair could look like this:
u: (how be you) Fine thank you.
While a slightly more complex example could look like this:
s: PETAPET(!not _~verb _[dog cat]) Wait, you can _0 a _1?!
A bit clarification of the syntax if you are not familiar with it:
- We always use canonical, lower-case version of words: “dog” will match “Dog” as well as “dogs”;
- Same goes for verbs and using them in their infinitive forms let CS match all possible forms and variations;
- Operators such as “!” and “*” are used to expand or restricts matches in different ways (i.e., what we were saying about boolean conditions);
- The very first letter followed by a semicolon indicate what kind of sentences to look for; a question, a sentence or either;
- Underscores capture inputs that can be reused by the bot;
- Tildes mark concepts encompassing many words under an umbrella term;
- Square brackets tells CS to look for only one of the contained word
- A capitalized word after the semicolon create a rule label that can be called directly by using the ^reuse function
It is important to remember that by default, CS will erase rule/response pairs as they are used to avoid letting the bot repeat itself on similar or identical inputs; each rule matches an input will be deleted for the duration of the conversation. This can be avoided on certain rule/response by using the ^keep and ^repeat function.
This is also where execution flow becomes important: the files are parsed by CS from top to bottom, so what is at the top will always be tested out before what comes after.
Concepts
Concepts are clusters of related and synonymous terms that we want considered as a group identified by a single term. Members of the concept could be argotic words, misspelled words, variations or even other concepts. CS will register a match on the concept if any of the terms are found in the input. In our CS files, this looks like this:
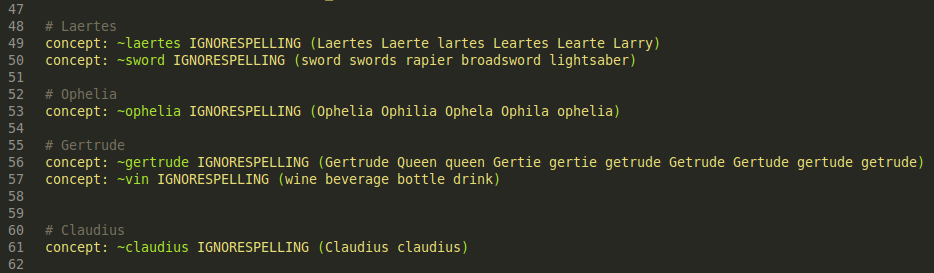
Fig. 5, Concepts in SimHamlet
Concepts are the green ~word. You can see that we are using the IGNORESPELLING modifier, which will mark the terms in parenthesis as canonical and not validate their spelling against the dictionary when compiling the bot. For a list of system concepts (CS 6.3) see this document and for more on concept modifiers, see page 6 (“Advanced Concept”) of the Advanced Manual.
It is also important to realize that since concepts are parsed as arrays and can contain an almost infinite number of words and concepts themselves, they are most of the time interchangeable with regular, single words. Let’s have a look at an example from SimProphet, first with the definition of a ~motanciens concept:

Fig. 6, Concepts in SimProphet
Which we might use like this:

Fig. 7, Using concepts in rules
On line 288, the script will look at the system variable %length and only go forward if it evaluate to more or equal to 3. Then it will simply look for any words in the ~motanciens concepts that is present in the input, and will output “You’re using it wrong” if it finds one.
On line 289, the script will look for any word that is present in ~motanciens and, if there is one, will evaluate to true AND captures the word (remember the what the underscore does). It then uses it in the response by using the form ‘_0. In practice this means that the conversation could go like this:
Player: my god is super ulmash
SimProhet: Sorry to be that guy, but you’re misusing ulmash.
In other words, any matched word from the concept can be captured and reused as is, without reference to the concept it is part of.
Variables
There is four types of variable in CS:
- System variables, prefixed with %
- Temporary variables, prefixed with $$
- Regular system-wide variable, prefixed with $
- Temporary variable for captured words from input, with the form _0, _1, _2, etc
As we’ve seen, variables are vital to the progression of our game. They also make the responses more engaging and personal. This is quite obvious in SimProphet as a lot the the content is generated by the user: god name, follower names, holidays, sacred places, etc. This create supplemental challenges, as some user input needs to be registered exactly as they are typed, even when they are not real words, while other need to be conjugated or made plural:

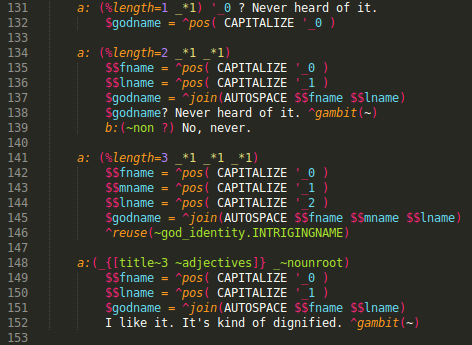

Fig. 8, Variables in SimProphet
I’ve only included parts of the routine. Line 68 is the first line that is served to the user: the rule name GODNAME and the lack of any conditional in the rule hint to the fact that this rule is invoked with the ^gambit function.
To make sure that the matched content will not be corrected, we change the parsing system by modifying the $token system variable on line 71, omitting DO_SPELLCHECK for the duration of this rule (remember the linear execution), adding it back at the end on line 173. Since this line is matched every time and used only to reset the $token system variable, we move the respond to the next gambit available in the current topic with the ^gambit rule.
Now line 131, 134 & 141. They are variation of the same need: we want to break apart each component of the god name, so we must capture them individually. First with evaluate the length, then capture exactly one word (_*1) on line 131. With the construct ‘_0, we make sure to use the literal rather than canonical form. The splitting allows us to capitalize each word, then join them into our permanent $godname variable (line 132, 137 & 145).
After adding the content to $godname, we have three slightly different behaviors. In the first example (line 132) we offer no response, so execution will move down to the next match in line (in this case, line 173). In the second example (line 138), assuming a $godname variable of “Beetlejuice”, the character will respond “Beetlejuice? Never hard of it”, then CS will affix the next gambit available in this topic. Finally, the last match will simply responds with the response in the ~god_identity topic named INTRIGINGNAME (line 146).
Special Needs
To illustrate other possible usage and how they affect the games made at LabLabLab, let’s look at the z_pronouns.top file in A Tough Sell:
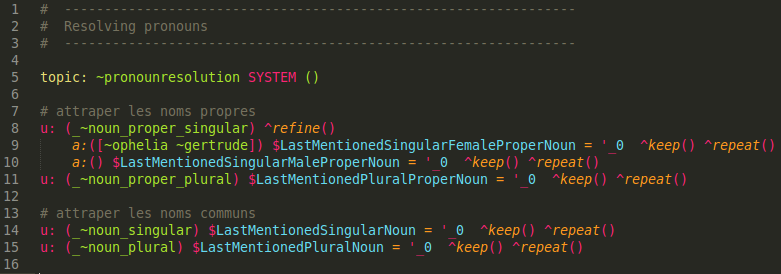
Fig. 9, Pronouns resolution in SimHamlet
None of these rules output a response, instead they parse the input for proper nouns and assign them to variables that will be used elsewhere. Since the control script detects that no response has been found, it keeps searching just as it normally would.
The ^refine function act as a filter that passes the query along further: it first looks for a match in ~noun_proper_singular, and if it finds one move the exact same input to the rejoinders (lines 9 & 10) where they are further processed. This is not foolproof however, as the name & pronouns could be inferred or they could not be present in ontologies such as ~noun_proper_singular or ~noun_plural. For example, someone playing A Tough Sell might have this hypothetical exchange:
Player: This apple looks good.
Snow White: Yes it does! I got it from the store.
Player: It’s very red.
Trying to match the last sentence, which would be parsed as “it be very red”, might not trigger anything in the apple topic where we want to be looking: nowhere in the query does the word “apple” appears. Our mechanism from above is more efficient combined with topic specific pronoun marking.
What we want to be doing essentially this: for all input in the current topic, replace all pronouns by what we think they point to. One way to do this is to simply parse and replace the terms:
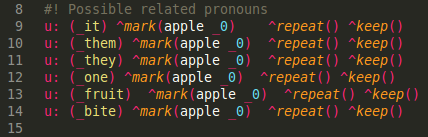
Fig. 10, Pronoun marking
As you can tell by the line numbers, this is at the top of the file: all inputs that are made while in this topic, regardless of their terms, will go through these six lines. If any of the words highlighted in yellow are found, they will be replaced by apple. Adding the ^repeat and ^keep function insures that CS does not discard these lines after they have been matched once. Since there is no response given, the control script will automatically keep searching for a response.
This brings us to a specific need in the LabLabLab projects: in narrative driven games a lot more than in regular chatbots, it is central to keep track of the subject.
Progression
While chatbots need to follow certain narrative arcs to keep up with the conversation, keeping track of progress is a lot more important in games, as they move towards defined goals. How do you bring this behavior out in a stateless system and that is designed to juggle with multiple topic at once? Luckily for us CS has an extensive variable system. Let’s break down the first part of a rule in SimProphet that uses lots of variable, the rules that register the name of the followers of your god:
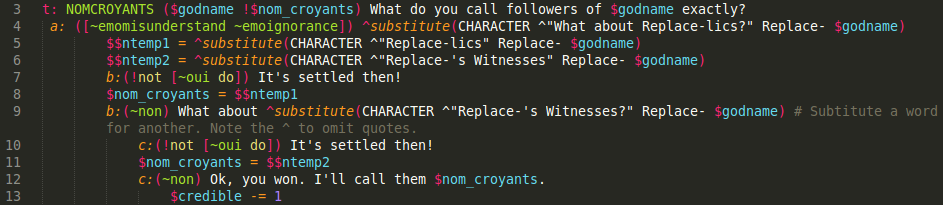
Fig. 11, Variable in SimProphet
This is a gambit named NOMCROYANTS (line 3, note the t:), which means that the bot will offer this response if:
- All conditions in parenthesis are evaluated to true when execution reaches this line;
- The bot has been explicitly told to try a gambit and reach this line without a response yet;
- The bot has been explicitly told to use this gambit through the ^gambit function;
Again, let’s assume that $godname has been set to “Beetlejuice” and walk through this rule:
- Since $godname is set and evaluate to true but our believers name variable is empty ($nom_croyant is false), then we respond with “What do you call followers of Beetlejuice exactly?”;
- The following rejoinder (line 4) matches only if the bot find a term from ~emmomisunderstand or ~emoignorance within the input. For example if the user respond “I don’t know” to “What do you call followers of Beetlejuice exactly?”, the bot will respond “What about Beetlejuicelics?”;
- On line 4 & 5, we create placeholder variables that will hold variations of the believers name: $$ntemp1 will become “Beetlejuicelics” and $$ntemps2 will become “Beetlejuice’s Witnesses”;
- Then if if user agree that it’s a good name (line 7) our actual variable, $nom_croyants, will take the value from $$ntemp1 (line 8);
Since variables can be either words or numerical values, we can use them to track and change gameplay properties and interface values, like it is done on line 13. As previously mentioned, this is very important in a game as an end state has to be reached. By using variables and changing them on certain inputs or responses, we collect data that we can feed back to the interface (as ways to keep the score) or the the chatbot itself (as a way to trigger responses).
Part Of Speech (POS)
We’ve seen with variables how to capture, assemble and proceed after matching terms that we want to reuse. But what about when we want to modify them according to context? We need to rely on the ^pos function (page 22). Some example with verbs:
s: ([teach show] * you * [_~verb ~vision_verbs act~1]) I’ve always wanted to ^post[VERB _0 INFINITIVE).
So that with an input of “I will teach you juggling” we will receive a response of “I’ve always wanted to juggle.” The ^pos function can also be used with nouns nouns:
s: (<<~dieu ~punition _ennemis>>) $godname would do that? I have tons of ^pos(NOUN _0 PLURAL)!
Still with a $godname of “Beetlejuice”, an input of “God will punish any rival” will receive a response of “Beetlejuice would do that? I have tons of rivals!”
Unity
The front-facing part of our games has been crafted using Unity, a 2D/3D engine and development environment. Unity has quickly become the defacto framework used to create independent games. It offers incredible flexibility with regard to content (file types, platforms, scripting languages) and always has had a free version. While Unity is now in version 5.3.X, most of the development was done with versions 4.X.X
Interface
The user-facing interface can be anything that communicate with our CS back-end: as one can see in the CS examples, the interface can be completely web based and quite minimalistic. Our need for Unity was born out of the requirements of a richer game interface with asset caching, audio, animations, keyboard inputs and so forth. This distinction between what effectively is the game engine (ChatScript) and the interface (Unity), opens up the possibility of integrating middleware components as well, such as analytics and voice recognition.
Another benefit is that the two systems can be updated independently; the CS components can be updated often, while the interface can be updated on slower schedule. This removes a lot of the annoyances of having to upload updated build every time the chatbot is updated (which happens often).
In its Unity interfaces, LabLabLab first used a mix of JS and C#, but finally transitioned into a uniform C# codebase for SimHamlet. Because of certain limitations early on, the connection to the CS back-end has been done in all three game through a PHP file that deals with the socket communication. This file offers an endpoint for our Unity interface to hit with a request and receive responses. It is likely that this could be replaced by a complete C# implementation, thus bypassing the need of a PHP server altogether. There is also the possibility of using more of a fully-featured proxy to communicate with CS for example.
Communication
Beside sending inputs and getting responses, other informations need to be exchanged between the CS and Unity, such as the state of interface objects or the current game status. This could be done in countless ways. LabLabLab decided to embed specific keywords in the responses, which are in turn parsed by the interface and removed from the final output:

Fig. 12, Interface cues embeded in response text, from SimHamlet
In the case of SimHamlet, CLol and CBored will be sent as part of the response’s body and indicate to Unity the need to animate the Gravedigger character appropriately. Then Unity will strip the command from the string before displaying it. Of course, these commands can take any form and merely act as action triggers from CS to Unity.

Fig. 13, Interface reaction on the CLol tag
Since the scope of LabLabLab’s games was quite restricted, this straightforward and simple implementation worked out well. However, it requires us to manage parsing on the front end and does not scale very well. To alleviate this, one can imagine a system topic containing a rule or macro appending interface variables to responses. With the help of a control script, this rule could be run after each and every rule/response pairs and be formatted to minimize front-end processing.
New web site
This web site is now up, so that is news.



